こんにちは。
ミルクおじさんです。
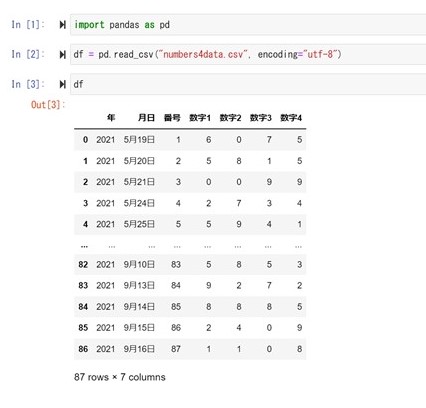
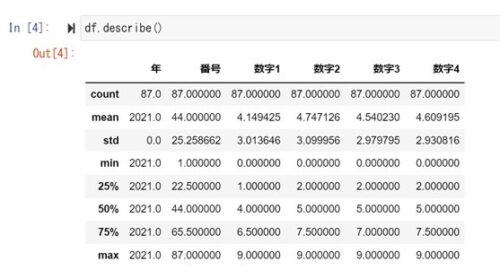
前回は、ナンバーズ4の基本統計量を示しました。
今回は、ロト6、ロト7、ミニロトを予想した同じ手法でナンバーズ4が予想できないか検証してみました。
数字が4つそれぞれ独立しているものを追えるかどうか?
楽しみです。
ではいってみましょう。
①Pythonにデータを読み込ませてモデルを作ります。
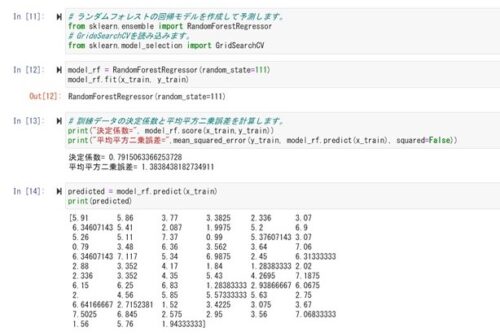
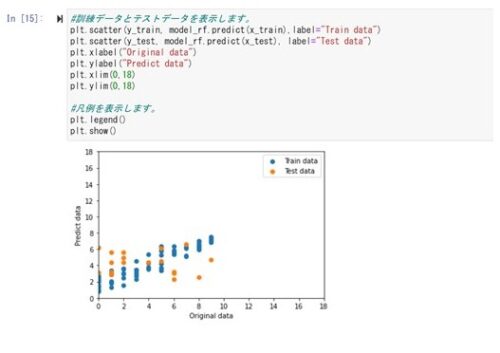
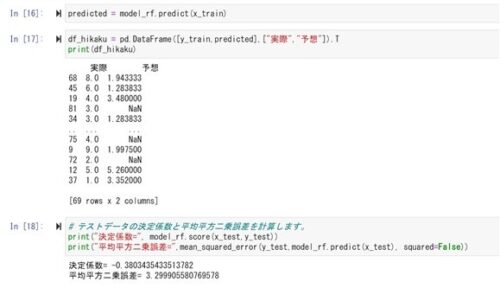
テストデータの決定係数がマイナスになってしまいました。
決定係数がマイナスになるのは計算次第ではありうるのですが、初めてのケースです。
データの数が少ないとマイナスになるケースがあるそうです。
②ランダムフォレストのハイパーパラメーターの最適化
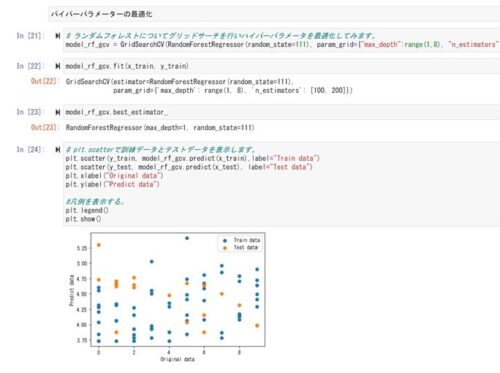
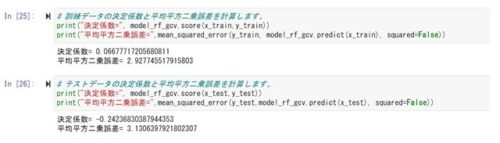
訓練データの決定係数がかなり小さくなりました。テストデータの決定係数もマイナスに、、、。
やはりデータ数が足りないか、、、、。
③エクセルで予想した数字の検証
次に自己相関係数を利用して、予想した数字の検証を行います。
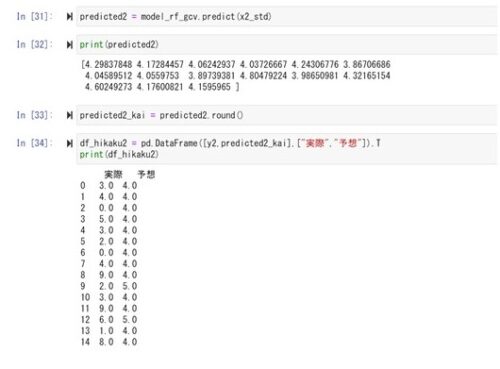
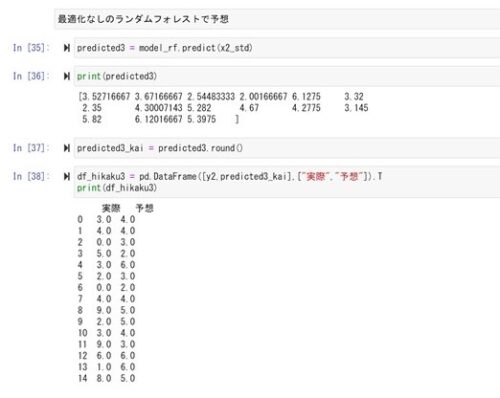
④表にまとます。
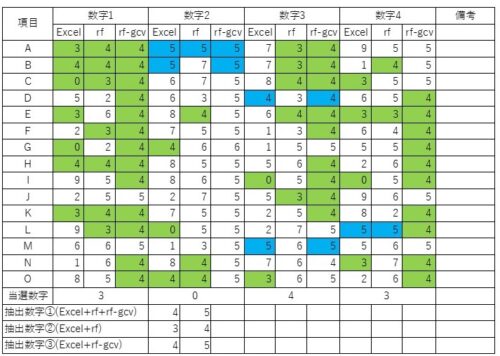
ランダムフォレストの結果は、4と5が多いですね。
もしかしたら、あまりにもぶれていて、モデルの中で平均の数値を出しておいた方が無難だ
という答えが多いのかもしれません。
0を抽出できないのもそのためかもしれません。
このままだと3,4,5,6しか抽出できないかも。
ナンバーズ4恐るべし。
データ数を上げて検証しなおします。
⑤まとめ
今回は、ナンバーズ4の直近のデータを予想してみました。
データ数が少なくて、安定していないことがわかりました。
次回は、データ数を多くして予想します。
ではまた。